外观
链表逆序,过目不忘
在算法的面试中,逆序是一个常见的主题。基于数组的逆序,基于链表的逆序,以及各种变种题目。 笔者最近也开始深入学习和研究这部分内容。 看了一些教程,自己也编写了一些代码,当初在leetcode刷过了,但其实没有理解到位。
重要
没有理解到位,那么在实际的面试中,还是会忘记。最后只得用stack这种结构去解决逆序问题。
逆序的方法
首先,传统的数组逆序,其实方案有很多种,效率较高的就是双指针,两头两个指针,来回交换位置。交换之后,两个指针相遇,逆序成功。
提示
金风玉露一相逢,便胜却人间无数。
千年之前,秦少游一定是个编程高手,O(∩_∩)O~
线性表的逆序最佳算法,相信你一旦看过一次,绝对不会忘记了。 那么链表逆序,会有类似的方法,让人一目了然吗?
智子突然用明澈的双眼直视逻辑——在此之前,她从来没有敢于正视过他——她回答了一个字,语气斩钉截铁:“有。”
”怎么做?!“
相信你也会有这样的疑问。我接下来就告诉你。
过目不忘的链表逆序
level1的做法:stack
由于逆序本身的特殊性,其实是一个后进先出的模型,可以使用栈来解决。很简单,只要在链表中引入一个栈,那么可以很方便的实现逆序。
public ListNode reverseV1(ListNode head) {
Stack<ListNode> s = new Stack<>();
ListNode p = head;
while (p != null) {
s.push(p);
p = p.next;
}
ListNode dummy = new ListNode(-1);
ListNode q = dummy;
while (!s.isEmpty()) {
q.next = s.pop();
q = q.next;
}
q.next = null;
return dummy.next;
}这版本的代码,真是很好理解,用一个栈,逆序后,pop出来,自然就变成了逆序的。
level2的做法:递归
通过栈做的话,感觉如隔靴搔痒。觉得不过瘾,就好像没有真刀真枪的上战场。是不是? 那么是不是有更加好的做法?不用到额外的数据结构?
提示
对的,这就是优化过程,我真正认为,也就是通过这种底层推导,能真正理解。连笔者的猪脑都能理解了,相信大家更没有问题了。
嗯,试试递归的办法。递归的思考模型,其实很简单,类似数学归纳法。数学归纳法虽然质朴,但是很有效。
递归的思考模型,也是一样的,回答下面的这3个问题即可
- 只有1个元素,如何逆序?
- 只有2个元素,如何逆序?
- 有k个元素,如何逆序?
答案也很简单
- 只有一个元素,那本身就是逆序了
- 只有2个元素,我专注处理我这第1个元素,将第1个元素挂在第2个元素之后,就完成了逆序。
- 有k个元素,我专注处理我这第1个元素,剩下k-1个元素先逆序,然后我把这个元素挂载这k-1个元素的最后就行了。 结束了。
在代码上,就变成了这样:
public ListNode reverseV2(ListNode head) {
if (head.next == null) {
return head;
}
ListNode cur = head; // 记录一下当前的节点
ListNode other = head.next; // 找到剩下的节点
head.next = null; // 断开链接,放置成为环链表
other = reverseV2(other); // 把剩下的链表逆序
ListNode tail = other; // 由于逆序后,返回的是链表的head,因此需要找到尾巴
while (tail.next != null) {
tail = tail.next;
}
tail.next = cur; // 把当前节点挂载在其余链表的尾部,结束
return other; // 返回新的头结点
}这个代码很好理解,只有中间那段循环不太好理解,但是也没啥难度。你仔细想一下就知道了。
现在分析一下这个做法的优劣:
优点是比较明确简单直接。缺点在于,执行效率较低,因为有多个while循环,虽然空间复杂度降低了很多,但是时间复杂度加了很多很多。
时间复杂度是个阶乘级别的,实际不建议使用。不过不要紧,咱们一步一步优化。
理解递归的本质,还是stack
在程序执行方法的过程中,递归结构,在现代编译器中,是通过 调用栈 进行支持的。不然怎么会支持你一层一层的调用下去呢。
// 1 -> 2 -> 3 -> 4 -> 5
reverseV2(Node 1)
└── reverseV2(Node 2)
└── reverseV2(Node 3)
└── reverseV2(Node 4)
└── reverseV2(Node 5)
5──┘
5>4──┘
5>4>3──┘
5>4>3>2──┘
5>4>3>2>1──┘上面就是调用关系,可以看到,高级语言解释器在执行这段代码,会引入一个stack 结构去支持这种递归调用,因此,在程序中,递归的过程不能太深,不然会出现经典的 stack over flow的异常。
注意
如果我就是要写这种代码,那么有没有解释器办法能优化这种无穷递归?嗯,有的(应该把)。
从上图来看,还是通过stack实现的,只不过是这种计算机语言(比如java)帮你做了这件事,本质好像没什么改善。
level2.5的做法:递归+尾插法
你把这段代码发到大模型去问问,都会说有问题,可以优化。优化的方案,其实就是使用所谓的 尾插法。
提示
上面的算法,问题就在于,递归返回的,是head节点,才导致了必须遍历到尾部,将新节点写进去。 有没有办法可以解决这个问题呢?
有的,下面这个办法就是解决思路。尾插法。笔者一步一步引导你思考下。千万别走神。
- 能不能操作递归返回的链表呢?
不能,如果一旦操作了,那么就相当于一定会回到了遍历,这是个悖论,一方面,要返回head,另一方面,又要操作tail。 - 那要怎么办,操作其他数据结构可以吗?
必须找到其他结构进行操作 - 找什么结构去操作呢?
从方法调用栈本身的结构分析一下试试看?
先看下递归是怎么运行的
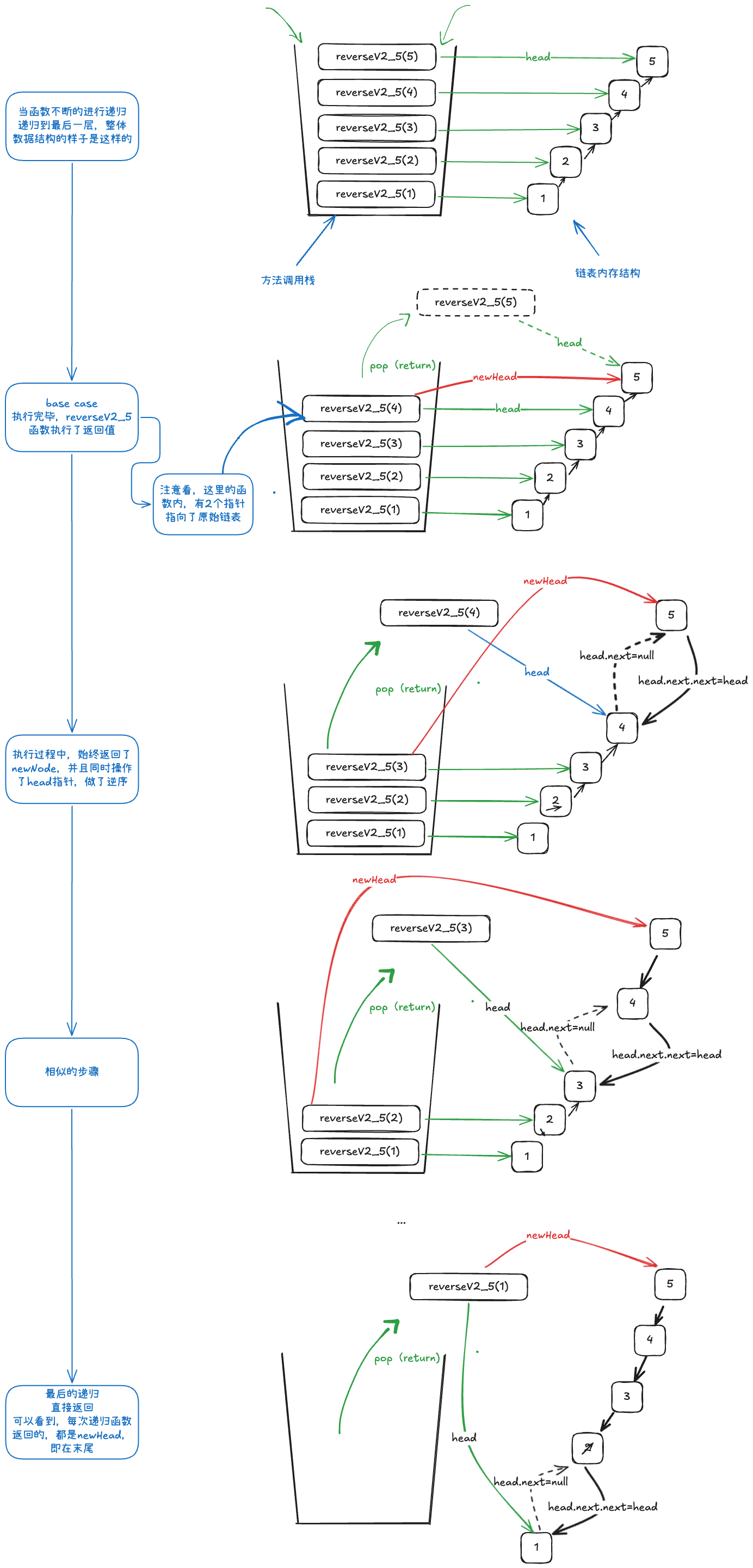
通过这张图,是不是突然有所顿悟?
- 在递归的时候,只要永远返回最后一个节点newNode,那么问题貌似就解决了。
- 递归本身,会将剩下链表的所有节点进行分拆,并且分别持有。
函数如下:
public ListNode reverseV2_5(ListNode head) {
if (head.next == null) {
return head;
}
// 递归反转剩余部分
ListNode newHead = reverseV2_5(head.next);
// 让 head.next(即原来的下一个节点)指向 head
ListNode tmp = head.next;
head.next = null;
tmp.next = head;
// 当然, 你也可以这样写:
// debug的时候,这一段会导致展示函数value的观察器报错,因为死循环了
// head.next.next = head;
// head.next=null;
return newHead;
}有点意思。这是充分利用了递归中的入参,以及递归的返回值,结果就把大量的循环消除掉了。有点意思。
level3的做法:迭代
既然,递归可以通过这样的方式减少在代码中的空间复杂度(其实没有真的减少),并且消除了额外的时间复杂度。
那么,我们参考这个代码的运作方式,应该也可以实现不额外占用空间的,空间复杂度 ,并且时间复杂度 的链表逆序。
你看,递归中,每次只操作2个元素,我们在迭代中也每次操作2个元素,不就完了吗
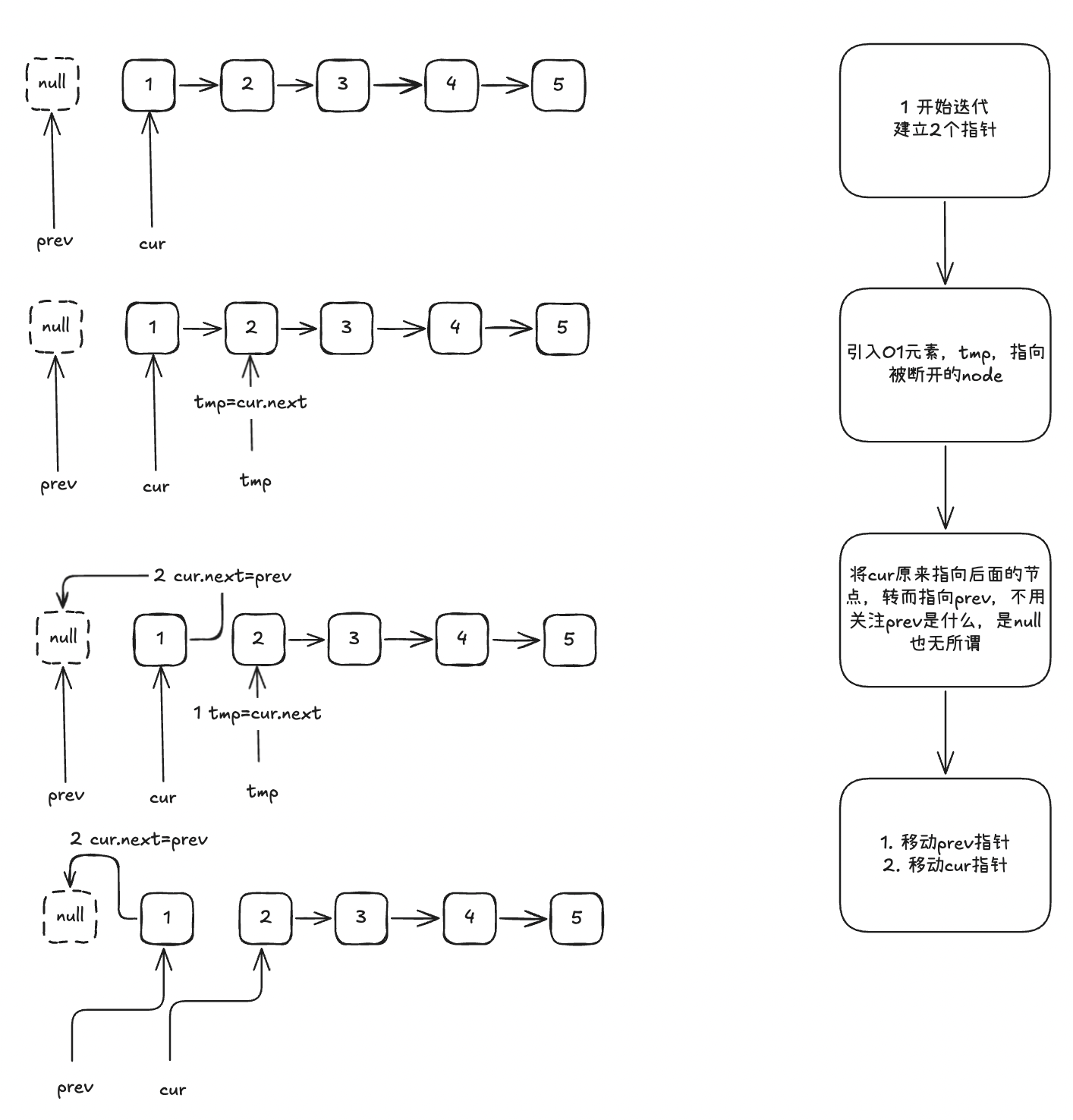
public ListNode reverseV3(ListNode head) {
if (head == null) {
return null;
}
ListNode prev = null;
ListNode cur = head;
while (cur != null) {
ListNode tmp = cur.next;
cur.next = prev;
prev = cur;
cur = tmp;
}
return prev;
}循环结束之后,可以看下两个指针的状态。
总结
到现在为止,笔者已经将逆序都说完了,最优的做法也推导出来了。在递归的做法中,其实和迭代尾插法是一样一样的。都是操作最后2个节点。
说是没有用额外的空间,相当于用现有的空间,构建了一个逆序链表。贪吃蛇。
以上。